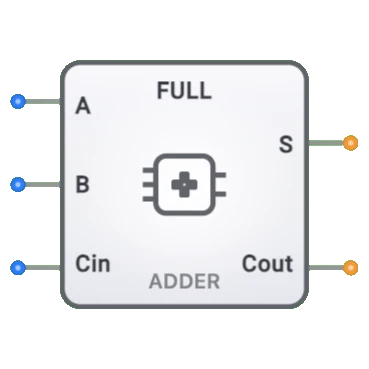
全加算器
概要
- 目的: 全加算器は、3つのバイナリ桁(2つの入力ビットと1つのキャリー入力ビット)の加算を行うデジタル組み合わせ回路です。合計ビットとキャリー出力ビットを生成し、配列で組み合わせることで任意のビット幅のバイナリ加算を可能にします。
- シンボル: 全加算器は、3つの入力(A、B、およびキャリー入力)と2つの出力(SumおよびCarry-out)を持つ「FA」とラベル付けされた矩形ブロックで表されます。
- DigiSim.io での役割: デジタル回路における算術演算の基本的な構成要素として機能し、配列で組み合わせることで任意のビット幅の加算演算を可能にします。
機能説明
論理動作
全加算器は3つのバイナリ入力(A、B、およびキャリー入力)を加算し、2つの出力を生成します:Sum(結果ビット)とCarry-out(オーバーフロービット)。
真理値表:
| Input A | Input B | Carry In | Sum | Carry Out |
|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 1 | 1 | 0 |
| 0 | 1 | 0 | 1 | 0 |
| 0 | 1 | 1 | 0 | 1 |
| 1 | 0 | 0 | 1 | 0 |
| 1 | 0 | 1 | 0 | 1 |
| 1 | 1 | 0 | 0 | 1 |
| 1 | 1 | 1 | 1 | 1 |
ブール式:
- Sum (S) = A ⊕ B ⊕ Cin(3つの入力すべてのXOR)
- Carry Out (Cout) = (A · B) + (Cin · (A ⊕ B))
入力と出力
- 入力:
- Input A: 1ビットの第1バイナリ入力。
- Input B: 1ビットの第2バイナリ入力。
- Carry In (Cin): 前の加算からの1ビットキャリー入力。
- 出力:
- Sum (S): 3つの入力を加算した結果を表す1ビットの合計出力。
- Carry Out (Cout): 合計が1を超えた場合のオーバーフローを表す1ビットのキャリー出力。
設定可能なパラメータ
- 伝搬遅延: 入力変化後に出力が変化するまでの時間。DigiSim.io はイベント駆動シミュレータでこの遅延をシミュレートします。
DigiSim.io での視覚的表現
全加算器は、左側に入力(A、B、およびCin)、右側に出力(SumおよびCout)を持つ矩形ブロックとして表示されます。全加算器として識別できるように明確にラベル付けされています。回路に接続されると、コンポーネントは接続ワイヤの色変化を通じてピンの論理状態を視覚的に示します。
教育的価値
主要概念
- バイナリ演算: キャリーを伴うバイナリ加算の基本プロセスを示します。
- 組み合わせ論理: 基本的な論理ゲートから複雑な演算を構築する方法を示します。
- マルチビット演算: 単一ビットコンポーネントをマルチビット演算のために組み合わせる方法を示します。
- キャリー伝搬: 算術演算におけるキャリービットの概念を紹介します。
学習目標
- キャリーの生成と伝搬を含むバイナリ加算の原理を理解する。
- 全加算器がキャリー入力を組み込むことで半加算器を拡張する方法を学ぶ。
- 複数の全加算器をカスケード接続してマルチビット加算器を作成する方法を理解する。
- ALUや電卓などの算術回路の設計に全加算器を適用する。
- ブール式と算術演算の関係を理解する。
使用例
- マルチビット加算: 複数の全加算器をカスケード接続して任意のビット幅のバイナリ数を加算する。
- リプルキャリー加算器: 全加算器を直列に接続してnビット加算器を作成する。
- バイナリ減算: 反転入力を持つ全加算器を使用して2の補数による減算を実行する。
- ALUの実装: 算術論理演算ユニットの加算機能を構築する。
- カウンタの設計: バイナリカウンタの実装に全加算器を使用する。
技術ノート
- 全加算器は2つの半加算器と1つのORゲートを使用して構成できます。
- カスケード接続された全加算器を通じたキャリー伝搬は、ビット幅が増加するにつれて遅延が増大し、リプルキャリー加算器のパフォーマンスのボトルネックとなります。
- 高性能が必要なマルチビット加算器では、キャリー先読み加算器やキャリー選択加算器などの代替アーキテクチャがキャリー伝搬遅延を軽減するために使用されます。
- 全加算器のクリティカルパスは通常キャリー生成論理を通過するため、キャリー伝搬が加算器速度の制限要因となります。
特性
- 伝搬遅延:
- Sum: 通常15-25ns(技術に依存)
- Carry Out: 通常10-20ns
- 消費電力: 中程度
- ファンアウト: 通常10-50ゲート(技術に依存)
- ゲート数: 標準的な実装で5つの基本ゲート(XOR 2個、AND 2個、OR 1個)
- 回路の複雑度: 中程度
- ノイズマージン: 中〜高(実装技術に依存)
実装方法
半加算器を使用した方法
- 2つの半加算器と1つのORゲート
- 最初の半加算器がAとBを加算し、2番目がその合計とCinを加算
- ORゲートが両方の半加算器からのキャリーを合成
基本論理ゲートを使用した方法
- XOR、AND、ORゲートによる直接実装
- 最適化された実装でゲート数を削減可能
トランジスタレベルの実装
- CMOS: 相補型MOSFETを使用
- TTL: バイポーラ接合トランジスタを使用
- 速度、消費電力、または面積に最適化
集積回路
- 74xxシリーズ論理ファミリで利用可能(例:74283 4ビット全加算器)
- より大きな算術コンポーネントの一部として組み込まれることが多い
FPGA/CPLD実装
- 専用の加算器ロジックまたはルックアップテーブル(LUT)を使用可能
- 合成ツールによる最適化が一般的
回路実装
半加算器を使用した構成
graph LR
InputA[Input A] --> HA1[Half Adder 1]
InputB[Input B] --> HA1
HA1 -->|Sum1| HA2[Half Adder 2]
CinPin[Carry In] --> HA2
HA1 -->|Carry1| OrGate[OR Gate]
HA2 -->|Carry2| OrGate
HA2 -->|Sum| SumOut[Sum Output]
OrGate --> CoutPin[Carry Out]
基本ゲートを使用した構成
graph TB
InputA[Input A] --> XorGate1[XOR Gate]
InputB[Input B] --> XorGate1
XorGate1 --> XorGate2[XOR Gate]
CinPin[Carry In] --> XorGate2
XorGate2 --> SumOut[Sum]
InputA --> AndGate1[AND Gate]
InputB --> AndGate1
XorGate1 --> AndGate2[AND Gate]
CinPin --> AndGate2
AndGate1 --> OrGate[OR Gate]
AndGate2 --> OrGate
OrGate --> CoutPin[Carry Out]
応用
マルチビットバイナリ加算
- カスケード接続してリプルキャリー加算器を形成
- 算術論理演算ユニット(ALU)で使用
- CPUの整数演算に不可欠
減算回路
- 反転入力とキャリー入力を1に設定して使用
- 2の補数減算の基盤を形成
算術論理演算ユニット(ALU)
- CPU算術演算のコアコンポーネント
- 加算、減算、および関連演算に使用
アドレス計算
- メモリアドレス計算に使用
- プログラムカウンタのインクリメントに利用
カウンタとインクリメンタ
- デジタルカウンタで使用
- ステートマシンで利用
デジタル信号処理
- 積和演算で使用
- デジタルフィルタのコンポーネント
エラー検出/訂正
- パリティとチェックサム計算に使用
- CRCおよびECC回路のコンポーネント
制限事項
キャリー伝搬遅延
- カスケード(リプルキャリー)実装では、キャリーが各段を通過して伝搬する必要がある
- マルチビット加算器のパフォーマンスを制限する可能性がある
- キャリー先読み加算器などのより高速なアーキテクチャがこの制限に対処
消費電力
- ゲート数の増加により半加算器より高い
- 高速または大きなビット幅の加算器では顕著になる可能性がある
関連コンポーネント
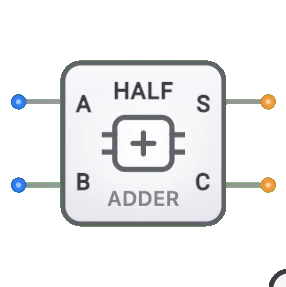
- 半加算器: キャリー入力のないシンプルなバージョン
- リプルキャリー加算器: 直列に接続された複数の全加算器
- キャリー先読み加算器: より高速なキャリー伝搬を持つ高度な加算器
- キャリー選択加算器: 複数の結果パスを使用して速度を最適化した加算器
- キャリースキップ加算器: スキップロジックを使用してキャリー伝搬を改善した加算器
- バイナリカウンタ: カウントのために加算器を使用する順序回路
- 算術論理演算ユニット(ALU): 算術演算のために加算器を組み込んだもの