命令レジスタ (IR)
概要
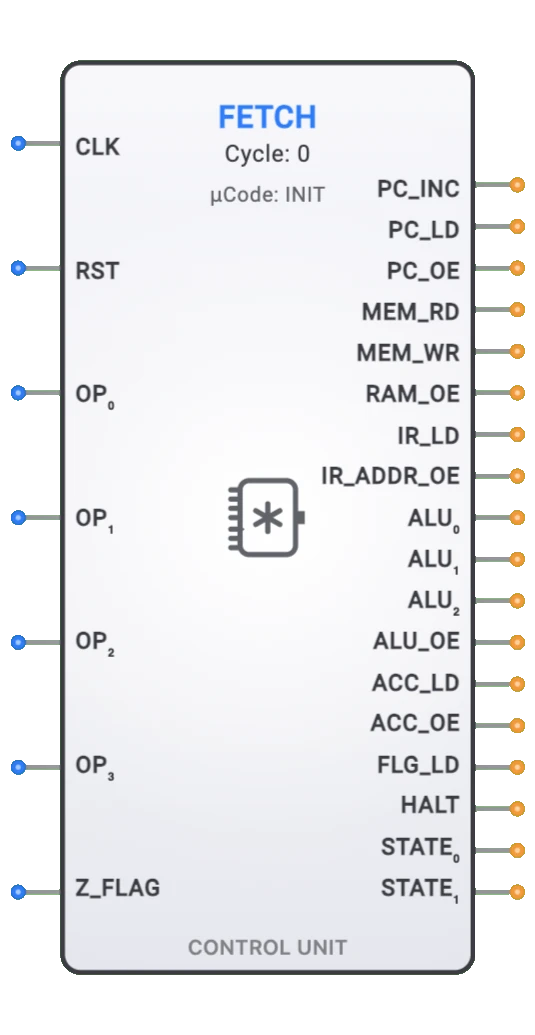
- 目的: 命令レジスタ (IR) は、メモリからフェッチされた機械語命令を、制御ユニットによるデコードおよび実行中に一時的に保持するCPU内の専用レジスタです。
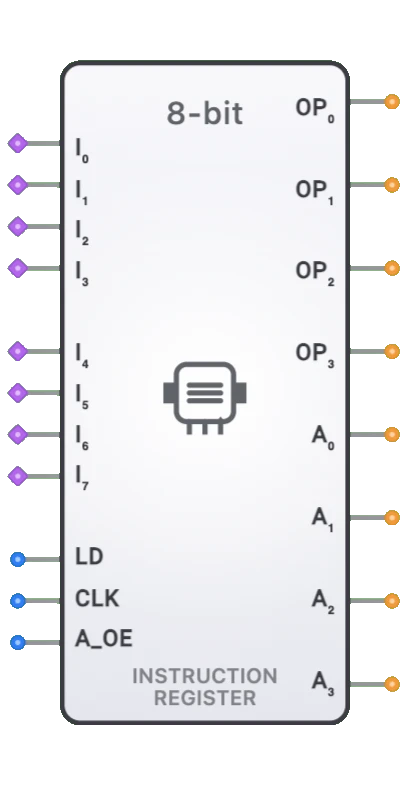
- シンボル: 命令レジスタは、メモリからのデータ入力、クロック、およびロードイネーブルの入力を持ち、デコーダへの命令ビットを出力する矩形ブロックで表されます。
- DigiSim.io での役割: CPU設計における重要なコンポーネントとして機能し、命令サイクルのフェッチ段階とデコード段階を結び、命令のオペコードとオペランドへの安定したアクセスを提供します。
機能説明
論理動作
命令レジスタは、フェッチサイクル中にメモリからの命令データをキャプチャして保持し、デコードおよび実行サイクルを通じて命令デコーダで利用可能にします。主にロード制御付きの記憶素子として機能します。
機能表:
| LD | CLK | A_OE | 動作 | Opcode (OP0-OP3) | Address (A0-A3) |
|---|---|---|---|---|---|
| 1 | ↑ | X | 新しい命令をロード | Loaded Data[3:0] | Loaded Data[7:4] or Hi-Z |
| 0 | ↑ | X | 現在の値を保持 | Current Value | Current Value or Hi-Z |
| X | 0 | X | 変化なし | Current Value | Current Value or Hi-Z |
| X | X | 1 | アドレス出力イネーブル | Current Value | Current Value |
| X | X | 0 | アドレス Hi-Z | Current Value | Hi-Z |
注: ↑ はクロックの立ち上がりエッジ、X は「ドントケア」条件を表します
入力と出力
入力:
- I0-I7: フェッチされた命令を受け取るためにメモリデータバスに接続された8ビットデータ入力。
- LD: アクティブ時に新しい命令のロードを有効にする1ビットのロードイネーブル入力。
- CLK: ロード動作を同期させる1ビットのクロック入力。
- A_OE: アドレスビットが出力に駆動されるかどうかを制御する1ビットのアドレス出力イネーブル。
出力:
- OP0-OP3: 制御ユニットにオペレーションコードを提供する4ビットのオペコード出力(常に有効)。
- A0-A3: アドレス情報を提供する4ビットのアドレス出力(A_OEで制御)。
- オペコード出力は、制御ユニットが即座にアクセスする必要があるため、ロード後常に利用可能です。
- アドレス出力は、メモリ操作中のバス共有のためにA_OEを使用してトライステートにできます。
設定可能なパラメータ
- レジスタ幅: IRが格納できるビット数。CPUの命令ワードサイズに一致します。
- クロックエッジ感度: レジスタが立ち上がりエッジまたは立ち下がりエッジに応答するかどうか。
- ロード動作: ロード制御信号がクロックとどのように相互作用するか。
- 伝搬遅延: トリガーイベント後に出力が変化するまでの時間。
DigiSim.io での視覚的表現
命令レジスタは、左側にラベル付きの入力(DATA[n:0]、CLK、LOAD)、右側に出力(IR_OUT[n:0])を持つ矩形ブロックとして表示されます。クロック入力は通常、エッジ感度を示す三角形のシンボルで示されます。回路に接続されると、コンポーネントは出力に表示される命令値と接続ワイヤの色変化を通じて現在の状態を視覚的に示します。
教育的価値
主要概念
- 命令サイクル: CPUのフェッチ・デコード・実行サイクルにおける重要な段階を示します。
- 命令デコード: 機械語命令が解釈のためにどのように準備されるかを示します。
- CPUアーキテクチャ: CPU制御ユニットの基本コンポーネントを紹介します。
- 逐次処理: CPUを通じてデータが離散的な段階で流れる方法を示します。
- 命令セットアーキテクチャ: 機械語命令がどのように処理されるかを視覚化するのに役立ちます。
学習目標
- CPU実行サイクルにおける命令レジスタの役割を理解する。
- CPU動作中に命令がどのようにキャプチャされ安定して保持されるかを学ぶ。
- IRがメモリおよび命令デコーダとどのようにインターフェースするかを理解する。
- シンプルなCPUアーキテクチャの設計にIRの概念を適用する。
- 命令フォーマットとCPU構成の関係を理解する。
使用例
- 基本的なCPU設計: フェッチ・デコード・実行サイクル実装のコアコンポーネント。
- 命令デコード: デコーダ回路に安定した命令データを提供する。
- パイプラインアーキテクチャ: CPUパイプラインでフェッチ段階とデコード段階を分離する。
- マイクロコード実装: 制御ユニットがマイクロオペレーションをステップ実行する間、命令を保持する。
- 教育用CPUモデル: CPU動作の基本原理を実演する。
- ハードワイヤード制御ユニット: 組み合わせ制御論理に命令ビットを直接提供する。
技術ノート
- 命令レジスタの幅は、プロセッサアーキテクチャの命令サイズに一致します。
- IRは通常、命令サイクルのフェッチフェーズ中にロードされます。
- シンプルな非パイプラインCPUでは、IRは各命令をその実行期間全体にわたって保持します。
- パイプラインアーキテクチャでは、異なるパイプラインステージに複数のIRが存在する場合があります。
- IRの出力は、命令フォーマットに基づいて特定の意味を持つフィールドに分割されることが多いです。
- 一部の複雑な命令セットでは、可変長命令を処理するための追加ロジックが必要です。
- IRは制御ユニットをデータバスから隔離し、現在の命令が実行されている間にメモリを他の操作に使用できるようにします。
graph LR
DATA[Data Bus<br/>from Memory] --> IR[Instruction Register]
CLK[Clock] --> IR
LOAD[Load Enable] --> IR
IR --> OUT[Output to Decoder<br/>Opcode & Operands]
注: IRのサイズはアーキテクチャの命令サイズに一致します。出力は命令デコーダロジックにルーティングされます。
真理値表 / 機能表
IRは主に記憶素子として機能します:
| LOAD | CLK | クロックエッジでの動作 | IR 出力(次の状態) |
|---|---|---|---|
| 1 | ↑ | 入力データをロード | Input Data |
| 0 | ↑ | 現在の値を保持 | IR Output (Current) |
| X | 0/↓ | 変化なし | IR Output (Current) |
出力はロード操作の間で通常安定しており、命令デコーダに継続的に利用可能です。
特性
入力構成:
- データ入力 (I0-I7): フェッチされた命令を受け取るためにメモリデータバスに接続された8ビットのパラレル入力。
- ロードイネーブル (LD): フェッチサイクル中に命令をラッチするためにアサートされる制御信号。
- クロック入力 (CLK): 立ち上がりエッジでロード動作を同期させます。
- アドレス出力イネーブル (A_OE): バス共有のためのアドレス出力のトライステート動作を制御します。
出力構成:
- オペコード出力 (OP0-OP3): 4ビット出力でオペレーションコードを提供し、制御ユニットによる即時アクセスのため常に有効。
- アドレス出力 (A0-A3): 4ビット出力でアドレス情報を提供し、A_OE経由でトライステートにできます。
- オペコードビットは通常、命令デコードのために制御ユニットに直接ルーティングされます。
- アドレスビットは、有効時にメモリアドレッシングとジャンプ操作に使用されます。
機能:
- 現在フェッチされた命令を一時的に格納します。
- デコードおよび実行中に命令を安定して保持します。
- フェッチサイクル後のデータバスの変化から制御ユニットを隔離します。
- 命令デコーダに必要な生の命令ビットを提供します。
伝搬遅延:
- クロックから出力までの遅延: ロード操作中のクロックエッジ後に命令が出力で利用可能になるまでの時間。
- クロックおよびロード信号に対するデータ入力のセットアップ/ホールド時間要件。
回路の複雑度:
- コア: 命令幅のビットごとに1つのDフリップフロップで構成されるパラレル入力、パラレル出力レジスタ。
- LOAD信号の制御論理。
実装方法
- Dフリップフロップの配列: 最も一般的な方法で、命令ワードの各ビットに1つのDフリップフロップを使用し、共通のLOAD信号で同時にクロックされます。
- 標準レジスタIC: 市販のレジスタIC(例:74HC374、74HC574(8ビット命令用))を使用。
- FPGA/ASIC実装: より大きなCPU設計内でHDLコードから合成。
応用
- 命令デコード・実行サイクル: CPUのフェッチ・デコード・実行サイクルの中心的なコンポーネント。
- CPU制御ユニット: 命令デコーダロジックへの入力を提供し、CPUの他の部分の制御信号を生成します。
- パイプラインステージ: パイプラインプロセッサでは、IRは通常命令デコード(ID)パイプラインステージ内に存在します。
制限事項
- 固定幅: IRのサイズにより、CPUが直接処理できる最大命令サイズが決定されます。
- ボトルネック: 一部の古いアーキテクチャでは、IRへのフェッチがパフォーマンスのボトルネックとなる可能性があり、命令プリフェッチやパイプライニングなどの技術で対処されます。
回路実装の詳細
Dフリップフロップで実装された8ビットIR:
graph LR
D0[Data_In 0] --> FF0[D Flip-Flop 0]
D1[Data_In 1] --> FF1[D Flip-Flop 1]
D2[Data_In 2] --> FF2[D Flip-Flop 2]
D7[Data_In 7] --> FF7[D Flip-Flop 7]
CLK[Clock] --> FF0
CLK --> FF1
CLK --> FF2
CLK --> FF7
LOAD[Load Enable] --> FF0
LOAD --> FF1
LOAD --> FF2
LOAD --> FF7
FF0 --> OUT0[IR_Out 0]
FF1 --> OUT1[IR_Out 1]
FF2 --> OUT2[IR_Out 2]
FF7 --> OUT7[IR_Out 7]
すべてのフリップフロップは同じ Clock (CLK) と Load Enable (LOAD) 信号を共有します。
関連コンポーネント
- プログラムカウンタ (PC): IRにロードされる命令をフェッチするためのアドレスを提供します。
- メモリ (RAM/ROM): 命令を格納します。
- データバス: メモリからIRに命令を運びます。
- 制御ユニット: IRと命令デコーダを含みます。
- 命令デコーダ: IRの出力を読み取り命令を解釈します。
- ALU: デコードされた命令で指定された演算を実行します。
- レジスタ: IRに格納された命令内のフィールドで指定されたオペランドを保持する場合があります。