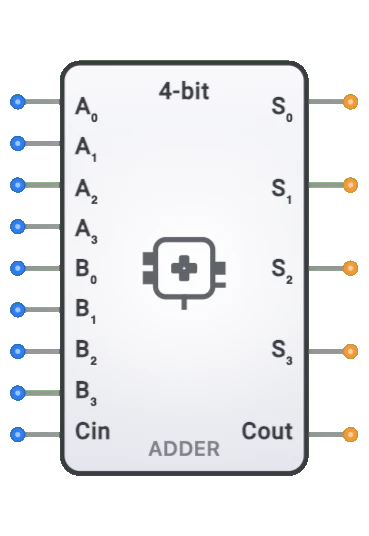
4ビット加算器
概要
- 目的: 4ビット加算器は、2つの4ビット数値の2進数加算を行うデジタル回路です。2つの4ビット入力(AとB)とオプションのキャリーイン(Cin)を受け取り、4ビットの和出力(S)とキャリーアウトビット(Cout)を生成します。
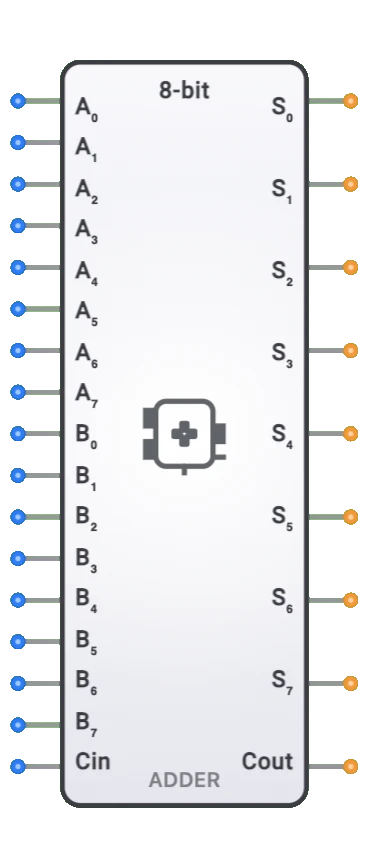
- シンボル: 4ビット加算器は、左側に2つの4ビットオペランド(A[3:0]とB[3:0])とキャリーイン(Cin)の入力を持ち、右側に4ビットの和(S[3:0])とキャリーアウト(Cout)の出力を持つ矩形ブロックで表されます。
- DigiSim.io での役割: 算術論理演算装置(ALU)の基本的な構成要素として機能し、プロセッサ、電卓、制御ユニットなどのデジタルシステムにおける各種算術演算を実装するための基盤を形成します。
機能説明
論理動作
4ビット加算器は A + B + Cin = (Cout, S) という式に従って2進数加算を実行します。各ビット位置では、AとBの対応するビットと前の位置からのキャリーが加算されます。
真理値表(サンプルエントリ - 組み合わせ数が多いため):
| A[3:0] | B[3:0] | Cin | S[3:0] | Cout | 備考 |
|---|---|---|---|---|---|
| 0000 (0) | 0000 (0) | 0 | 0000 (0) | 0 | ゼロ加算 |
| 0001 (1) | 0001 (1) | 0 | 0010 (2) | 0 | 単純な加算 |
| 1111 (15) | 0001 (1) | 0 | 0000 (0) | 1 | 16へのオーバーフロー |
| 1010 (10) | 0101 (5) | 0 | 1111 (15) | 0 | 範囲内の和 |
| 1111 (15) | 1111 (15) | 0 | 1110 (14) | 1 | 最大値+最大値 |
入力と出力
入力:
- A[3:0]: 4ビットの第1オペランド。
- B[3:0]: 4ビットの第2オペランド。
- Cin: 他の加算器とのカスケード接続またはインクリメント用の1ビットキャリー入力。
出力:
- S[3:0]: 4ビットの和の結果。
- Cout: 4ビットを超えるオーバーフローを示す1ビットキャリー出力。
設定可能なパラメータ
- 伝播遅延: 入力変化後に出力が変化するまでの時間。DigiSim.io のシミュレーション設定で設定可能です。
- 実装方法: バージョンによっては、速度とリソース使用量に影響する異なる内部実装(リップルキャリー、キャリー先読みなど)の選択が可能な場合があります。
DigiSim.io でのビジュアル表現
4ビット加算器は、左側に明確にラベル付けされた入力(A[3:0]、B[3:0]、Cin)と右側に出力(S[3:0]、Cout)を持つ矩形ブロックとして表示されます。回路に接続すると、コンポーネントはワイヤのカラーコーディングを通じて入力と出力の現在の値を視覚的に示し、ユーザーがシステムを通る2進数データの流れを追跡できるようにします。
教育的価値
主要概念
- 2進数加算: コンピュータが2進数の加算をどのように実行するかを実証します。
- キャリー伝播: キャリーが下位ビットから上位ビットへどのように流れるかを示します。
- デジタル演算: コンピュータ算術演算の基本的な構成要素を示します。
- オーバーフロー検出: 結果が利用可能なビット幅を超えた場合の検出概念を紹介します。
- モジュラー設計: 複雑な演算がより単純なコンポーネントからどのように構築できるかを例示します。
学習目標
- 2進数加算とそのデジタル回路での実装方法を理解する。
- キャリー伝播がデジタル加算器のパフォーマンスにどのように影響するかを学ぶ。
- 異なる加算器の実装とそのトレードオフを認識する。
- 4ビット加算器を算術回路と単純なプロセッサの設計に応用する。
- 固定ビット幅の演算でオーバーフローがどのように検出・処理されるかを理解する。
使用例
- 算術論理演算装置(ALU): CPU算術演算とアドレス計算のコアコンポーネント。
- 2進数カウンタ: 特定のカウントシーケンスを持つ同期カウンタの作成。
- デジタル信号処理: サンプル値計算と信号振幅演算。
- メモリアドレス生成: メモリシステムにおけるオフセットとアドレスの計算。
- 小規模演算回路: 電卓や小型プロセッサを実装するための構成要素。
- プログラムカウンタ: 単純なCPU設計でのプログラムカウンタのインクリメント。
技術ノート
- 4ビット加算器は速度と複雑さのトレードオフを持つ様々なアーキテクチャで実装できます:
- リップルキャリー加算器: 最も単純な実装ですが、ビット幅に対して線形の遅延があります。
- キャリー先読み加算器: 対数遅延で高速動作しますが、より複雑な回路が必要です。
- キャリー選択加算器: 速度とリソースの良いトレードオフ。
- 符号付き演算では、キャリーアウトはオーバーフローを正しく示しません。代わりに、結果の符号がオペランドと予期せず異なる場合にオーバーフローが発生します。
- 複数の4ビット加算器をカスケード接続して、1つの加算器のキャリーアウトを次の加算器のキャリーインに接続することで、より広いデータ(8ビット、16ビットなど)の加算を実行できます。
- DigiSim.io では、加算器の伝播遅延は実際の動作をシミュレートし、最悪の場合の遅延は最下位ビットから最上位ビットへキャリーが伝播する必要がある場合に発生します。
特性
- ビット幅:
- 4ビット動作(より広い演算のために拡張可能)
- 伝播遅延:
- リップルキャリー: O(n)遅延(nはビット数)
- 単一の全加算器の遅延の約4倍
- 数値範囲:
- キャリーインなしで0〜15の値を加算可能
- キャリーインありで最大16の値を処理可能
- 出力範囲:
- 和出力は0〜15の値を表す
- キャリー出力は結果が15を超えた場合を示す
- 消費電力:
- 中程度、実装技術に依存
- 加算時のスイッチングアクティビティに比例
- 回路の複雑さ:
- 中程度(4つの全加算器が必要)
- 各全加算器には2つの半加算器と1つのORゲートが必要
- 速度:
- キャリー伝播によって制限
- 最悪の場合はすべてのステージにキャリーがリップルする必要がある
- ハードウェアコスト:
- 単一の全加算器のコストの約4倍
- 通常合計約20〜28個の論理ゲート
実装方法
- リップルキャリー加算器
- 4つの全加算器をカスケード接続した最も単純な実装
- キャリーが最下位ビットから最上位ビットへ伝播
graph LR
A0[A0] --> FA0[Full Adder 0]
B0[B0] --> FA0
CIN[Carry In] --> FA0
FA0 -->|S0| S0[Sum 0]
FA0 -->|C0| FA1[Full Adder 1]
A1[A1] --> FA1
B1[B1] --> FA1
FA1 -->|S1| S1[Sum 1]
FA1 -->|C1| FA2[Full Adder 2]
A2[A2] --> FA2
B2[B2] --> FA2
FA2 -->|S2| S2[Sum 2]
FA2 -->|C2| FA3[Full Adder 3]
A3[A3] --> FA3
B3[B3] --> FA3
FA3 -->|S3| S3[Sum 3]
FA3 -->|COUT| COUT[Carry Out]
動作: キャリーはLSBからMSBへ各ステージを順次リップルします。
キャリー先読み実装
- キャリーを並列計算するより高速な実装
- キャリーを予測するために生成(G)と伝播(P)信号を使用
- 最悪ケースの遅延をO(n)からO(log n)に削減
集積回路
- 74xxシリーズロジックファミリで利用可能(例:74LS283)
- 最適化された内部構造を持つ専用4ビット加算器チップ
FPGA/ASIC実装
- ハードウェア記述言語を使用したカスタム実装
- 特定のパフォーマンス/面積のトレードオフに最適化可能
応用
算術論理演算装置(ALU)
- 算術演算を実行するコアコンポーネント
- 減算、比較などの他の回路と組み合わせて使用
マイクロプロセッサ設計
- CPU算術ユニットの基本部品
- アドレス計算とデータ操作での使用
デジタル信号処理
- 信号振幅の加算と混合
- フィルター係数の計算
デジタルカウンタ
- カウンタ値のインクリメントに使用
- メモリシステムでのアドレス生成
2進数電卓
- 基本的な加算演算
- より複雑な計算の基礎
エラー訂正回路
- チェックサム計算
- CRC(巡回冗長検査)実装
デジタル制御システム
- センサー入力の処理と制御出力の計算
- PIDコントローラ実装
制限事項
リップルキャリー実装での速度制限
- キャリーが各ビット位置を順次伝播する必要がある
- 最悪ケースの遅延はビット数に比例
オーバーフロー検出
- 標準実装ではオーバーフロー条件を検出しない
- 結果が範囲外になった場合を検出するための追加ロジックが必要
限られたビット幅
- 4ビットオペランドに制限
- より広い演算には複数のユニットが必要
減算機能なし
- 加算のみを実行
- 減算には追加ロジックが必要(例:2の補数)
消費電力
- キャリー伝播時の複数の遷移
- バッテリー駆動のアプリケーションでは懸念事項になる場合あり
回路実装の詳細
全加算器の実装
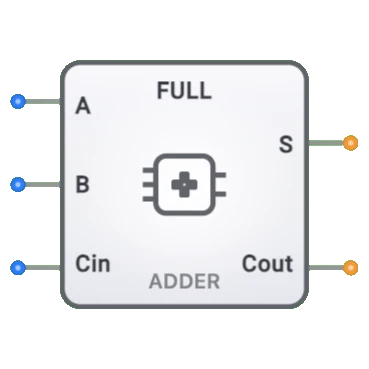
4ビットリップルキャリー加算器の4つの全加算器それぞれが以下を計算します:
Si = Ai ⊕ Bi ⊕ Ci
Ci+1 = (Ai · Bi) + (Ai · Ci) + (Bi · Ci)
ここで:
- Siは和ビット
- Ciはキャリーイン
- Ci+1はキャリーアウト
キャリー先読み実装
キャリー先読み加算器は以下を使用します:
Generate: Gi = Ai · Bi
Propagate: Pi = Ai ⊕ Bi
C1 = G0 + (P0 · CIN)
C2 = G1 + (P1 · G0) + (P1 · P0 · CIN)
C3 = G2 + (P2 · G1) + (P2 · P1 · G0) + (P2 · P1 · P0 · CIN)
COUT = G3 + (P3 · G2) + (P3 · P2 · G1) + (P3 · P2 · P1 · G0) + (P3 · P2 · P1 · P0 · CIN)
Si = Pi ⊕ Ci
関連コンポーネント
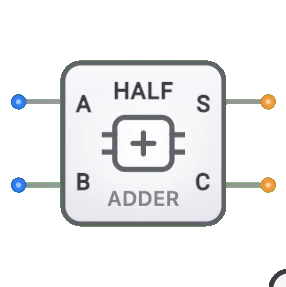
- 半加算器: キャリーインなしの単一ビット加算の基本構成要素
- 全加算器: キャリーインを持つ単一ビット加算の基本コンポーネント
- 8ビット加算器: より広いオペランド用の4ビット加算器の拡張バージョン
- 減算器: 2進数減算を実行する回路、しばしば加算器を使用して実装
- ALU: 他の算術・論理機能と共に加算器を組み込む包括的な回路
- BCD加算器: 10進数(BCD)数値用の特殊加算器
- キャリー先読みジェネレーター: キャリーを並列計算して加算を高速化
- 加算器-減算器: 加算と減算の両方を実行できる複合回路