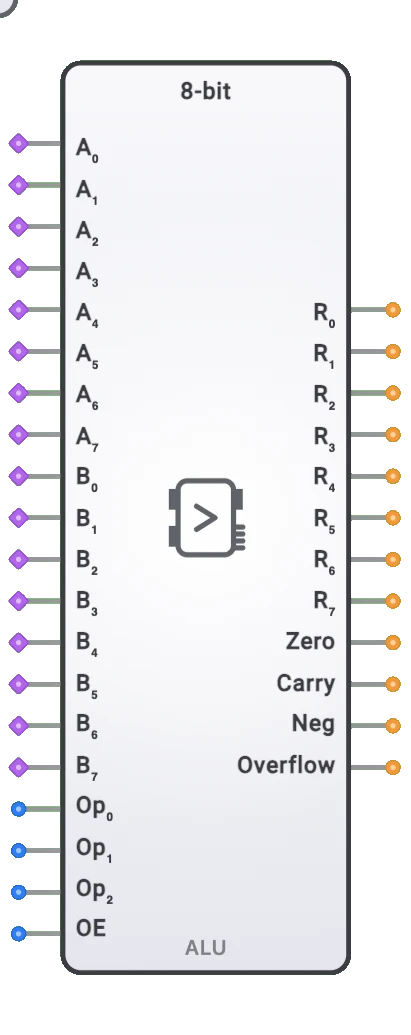
8ビット算術論理演算装置(ALU)
概要
- 目的: 8ビットALUは、8ビット2進数に対して算術演算と論理演算を実行します。制御信号に基づいて各種演算を実行し、デジタルシステムの計算コアとして機能します。
- シンボル: ALUは、2つの8ビットオペランド(AとB)と演算選択の入力を持ち、8ビットの結果とステータスフラグの出力を持つ矩形ブロックで表されます。
- DigiSim.io での役割: 8ビットALUはデジタル回路での計算を可能にし、プロセッサ、電卓、その他の計算システムを実装するために不可欠です。
機能説明
論理動作
8ビットALUは2つの8ビット入力を受け取り、演算制御入力で選択された演算を実行し、8ビットの結果とステータスフラグを生成します。これらのフラグは、結果がゼロかどうか、負かどうか、キャリーやオーバーフローがあったかどうかなどのプロパティを示します。
演算選択:
| OP2 | OP1 | OP0 | 演算 | 説明 |
|---|---|---|---|---|
| 0 | 0 | 0 | Y = A + B | 加算 |
| 0 | 0 | 1 | Y = A - B | 減算 |
| 0 | 1 | 0 | Y = A & B | ビット積(AND) |
| 0 | 1 | 1 | Y = A | B | ビット和(OR) |
| 1 | 0 | 0 | Y = A ^ B | 排他的論理和(XOR) |
| 1 | 0 | 1 | Y = ~A | ビット反転(Aの補数) |
| 1 | 1 | 0 | Y = A << 1 | 論理左シフト |
| 1 | 1 | 1 | Y = A >> 1 | 論理右シフト |
入力と出力
入力:
- A0〜A7: 8ビットの第1オペランド。
- B0〜B7: 8ビットの第2オペランド。
- OP0〜OP2: 実行する機能を決定する3ビット演算選択。
- SubIn: 減算入力制御信号。
出力:
- Y0〜Y7: 演算の8ビット結果。
- ゼロフラグ(Z): 結果がゼロのとき(すべてのビットが0)セットされます。
- キャリーフラグ(C): 演算でキャリーアウト(加算の場合)またはボロー(減算の場合)が生成されたときセットされます。
- ネガティブフラグ(N): 結果の最上位ビットが1(2の補数で負)のときセットされます。
- オーバーフローフラグ(V): 符号付き算術演算でオーバーフローが発生したときセットされます。
設定可能なパラメータ
- 伝播遅延: 入力変化と対応する出力変化の間の時間遅延。DigiSim.io でシミュレートされます。
DigiSim.io でのビジュアル表現
8ビットALUは、左側に入力、右側に出力を持つ矩形ブロックとして表示されます。その機能を識別するため「ALU-8BIT」と明確にラベル付けされています。入力ピン(A0〜A7、B0〜B7、OP0〜OP2)と出力ピン(Y0〜Y7、Z、C、N、V)は論理的なグループに配置されています。コンポーネントはすべての入力と出力の現在の状態を視覚的に示します。
教育的価値
主要概念
- 2進数演算: コンピュータが2進数の基本算術演算をどのように実行するかを実証します。
- ブール論理: 複数ビット値での論理演算の実装を示します。
- ステータスフラグ: 演算結果に関する情報を提供する条件コードの概念を紹介します。
- 計算構成要素: 複雑な演算がデジタルロジックを使用してどのように実装できるかを説明します。
学習目標
- デジタルシステムが算術演算と論理演算をどのように実行するかを理解する。
- 2進数演算とその結果の関係を学ぶ。
- ステータスフラグが演算結果について重要な情報をどのように提供するかを認識する。
- ALUの概念を単純な計算システムの設計に応用する。
- ALUがコンピュータシステムの広いアーキテクチャにどのように適合するかを理解する。
使用例
- 単純なCPU設計: ALUはCPUの計算コアを形成し、算術演算と論理演算を実行します。
- 電卓回路: 基本的な算術演算を実行する2進数電卓の実装。
- データ操作: マスキング、フィルタリング、値の変換のためのビット演算によるデータ処理。
- 条件テスト: ALUとそのフラグを使用してデータ値の特定の条件をテスト。
- 信号処理: スケーリング、オフセット調整、しきい値検出などの基本デジタル信号処理演算。
技術ノート
- 算術演算: 加算と減算はキャリー伝播を持つ全加算器を使用して実装されます。
- フラグ生成: ステータスフラグは演算結果とキャリーチェーンから導出されます。
- 演算レイテンシ: 異なる演算はわずかに異なる伝播遅延を持つ場合があり、加算と減算はキャリー伝播のために通常最も長くかかります。
- カスケード接続: 複数の8ビットALUを接続して、より広いデータ(16ビット、32ビットなど)での演算を実行できます。
特性
入力構成:
- 2つの8ビットデータ入力(A[7:0]とB[7:0])
- 3ビット演算選択入力(OP[2:0])
- 順次演算のためのオプションのクロック入力
- 連鎖算術演算のためのオプションのキャリーイン
- 専門機能のための追加制御信号を含む場合あり
- 使用されるロジックファミリと一致した入力負荷
- すべての入力は通常標準ロジックレベルを使用
出力構成:
- 8ビット結果出力(Y[7:0])
- ステータスフラグ出力:
- ゼロフラグ(Z): 結果がゼロのとき(すべてのビット0)セット
- キャリーフラグ(C): 演算でキャリーアウトが生成されたときセット
- オーバーフローフラグ(V): 符号付き算術演算がオーバーフローしたときセット
- ネガティブフラグ(N): 結果のMSB=1(2の補数で負)のときセット
- 複数のALUをカスケード接続するためのオプションのキャリーアウト
- 標準ロジックレベル出力
- 典型的なデジタル負荷を駆動可能な出力
- トライステート出力機能を含む場合あり
機能:
- 算術演算: 加算、減算、インクリメント、デクリメント
- 論理演算: AND、OR、XOR、NOT
- シフト演算: 論理左/右シフト、左/右ローテート
- 転送演算: Aを通過、Bを通過、クリア、セット
- 制御入力による演算選択
- 結果ステータスのためのフラグ生成
- 組み合わせ演算(登録されていない場合)
- 符号なしと符号付き演算の両方をサポートする場合あり
- より広いワード幅のためにカスケード接続可能
伝播遅延:
- 演算によって異なる:
- 加算/減算: 30〜50ns(最も複雑なパス)
- 論理演算: 15〜25ns(通常より高速)
- シフト演算: 20〜35ns(中程度の複雑さ)
- クリティカルパスは通常キャリー伝播を通じる
- フラグ生成は追加遅延を加える
- 技術依存(TTL、CMOSなど)
- 温度と電圧に敏感
- 最大遅延と典型的遅延の間の変動
- より広い演算のためのカスケード接続時に遅延が増加
- 演算によって異なる:
ファンアウト:
- データ出力は通常10〜20の標準負荷を駆動
- フラグ出力はより低い駆動能力を持つ場合あり
- 出力負荷は伝播遅延に影響
- 高ファンアウト状況ではバッファリングが必要な場合あり
- ロジックファミリの仕様と一致
- クリティカル信号には特別な注意が必要な場合あり
消費電力:
- 複雑さに基づいて中〜高程度
- 技術(CMOS、TTLなど)に依存
- クロックレートで動的電力が増加
- 演算依存(算術は通常より高い)
- 入力スイッチングアクティビティが電力に影響
- 古い技術では静的電力が重要
- アクティブなゲート数で電力が増加
回路の複雑さ:
- 複数の機能による高い複雑さ
- 大きな論理リソースが必要
- 広範な内部データパス
- 複雑な機能選択ロジック
- フラグ生成で追加の複雑さが加わる
- 複数の内部ステージ
- 統合設計により外部コンポーネント数を削減
- レジスタ統合によりさらに複雑さが増加
実装方法
ディスクリートロジック実装
- 基本ゲートとMSIコンポーネントから構築
- 各演算タイプごとに別々の回路
- 演算結果を選択するマルチプレクサ
- 各結果のフラグ生成ロジック
- ALUの原理を示す教育的実装
- コンポーネント数が多い
- 低速に限定
- ALUアーキテクチャを理解するのに有用
集積回路実装
- 専用ALU IC
- 例: 74181(4ビットALU、カスケード接続可能)、74382
- 様々な機能と演算セット
- 異なるロジックファミリで利用可能
- 外部コンポーネント数を削減
- ディスクリート設計より信頼性が向上
- タイミングと負荷が適切に特性評価
- 古いまたは教育的なコンピュータ設計でしばしば使用
キャリー先読み設計
- 高度なキャリー伝播技術
- クリティカルパスの遅延を削減
- 並列プレフィックス加算器構造
- より高速な算術演算
- より複雑なゲート構造
- パフォーマンスのためのゲート数増加
- 高パフォーマンス実装に一般的
- 様々なキャリー先読みスキームが可能
カスケード実装
- 複数のより小さなALUを組み合わせる
- ユニット間のキャリーチェーン
- フラグ結合ロジック
- より広いワードサイズへのモジュラーアプローチ
- 標準コンポーネントを効率的に使用
- パフォーマンスと複雑さのバランス
- 伝播遅延が増加する場合あり
- より広い実装でコスト効率的
FPGA/ASIC実装
- HDLベース設計(VHDL、Verilog)
- ターゲット技術に最適化
- 専用算術構造を活用
- 設定可能な演算セット
- 異なるビット幅にスケーラブル
- FPGAの高速キャリーチェーンを活用可能
- 特定の要件にカスタマイズ可能
- リソース効率の高い実装
マイクロコード制御ALU
- マイクロコードで制御される演算
- より柔軟な演算セット
- 潜在的に遅い実行
- 複雑な演算をマイクロ演算に分解
- CISC プロセッサ設計に一般的
- 新しい演算の追加が容易
- より高い制御オーバーヘッド
- 複雑な命令セットに適している
ビットスライス実装
- ビットスライスプロセッサコンポーネントから構築
- 異なるワード幅のためのモジュラー設計
- カスタムプロセッサのための古典的アプローチ
- 例: AMD 2901、74LS181
- スライス間の標準化されたインターフェース
- 柔軟な設定オプション
- 教育目的に適している
- 歴史的に重要なアーキテクチャ
応用
中央処理装置(CPU)
- コア計算要素
- 命令実行
- アドレス計算
- プログラムカウンタ操作
- 条件演算
- ループ制御
- 分岐のためのフラグ生成
マイクロコントローラ
- 組み込み計算
- I/O処理
- データ変換
- プロトコル実装
- センサーデータ処理
- 制御アルゴリズム
- リアルタイム操作
デジタル信号処理
- 信号フィルタリング
- 変換(FFT、DCT)
- 畳み込み演算
- サンプル操作
- 係数乗算
- 蓄積演算
- 信号生成
グラフィックス処理
- 座標変換
- ピクセル操作
- ジオメトリ計算
- ブレンディング演算
- テクスチャマッピング
- カラースペース変換
- ベクター演算
カスタム計算機
- アプリケーション固有プロセッサ
- ハードウェアアクセラレータ
- FPGAベースの計算
- 専門アルゴリズム
- データフローアーキテクチャ
- 並列処理要素
- 高パフォーマンス計算
教育システム
- コンピュータアーキテクチャ学習
- デジタル設計の教授
- 実践的なプロセッサ設計
- アルゴリズム実装
- パフォーマンス分析
- ハードウェア/ソフトウェアインターフェースの理解
- コンピューティングの基礎
テストと検証
- 回路テスト
- 故障検出
- 論理比較
- シグネチャ解析
- 組み込み自己テスト
- 製造テスト
- 機能検証
制限事項
パフォーマンス制約
- キャリー伝播遅延が算術速度を制限
- 順次演算実行(一度に1つ)
- 固定ワードサイズではより大きな演算に複数サイクルが必要
- 演算選択オーバーヘッド
- 算術演算を通じるクリティカルパス
- フラグ生成で遅延が加わる
- 演算速度は機能によって異なる
アーキテクチャの制限
- 演算セットが限定的
- 固定ビット幅ではカスケード接続が必要
- 基本演算では複雑なタスクに命令シーケンスが必要
- 演算間のフラグ依存
- ユニット内の並列性が限定的
- ワードレベルでの演算粒度
- 汎用的な性質が専門最適化を犠牲にする
実装の課題
- 複雑な制御ロジックが必要
- 大きなルーティングリソースが必要
- 高いゲート数で消費電力が増加
- 複数の演算による複雑なテスト
- すべての演算にわたるタイミング検証
- パフォーマンスと面積のトレードオフ
- キャリーチェーンを通じるクリティカルタイミングパス
動作上の制約
- 浮動小数点の直接サポートなし
- 精度が限定(8ビット)
- 多倍精度演算にはソフトウェアアルゴリズムが必要
- 除算や乗算の直接サポートなし
- 複雑な演算には複数のステップが必要
- 限定されたデータ型のサポート
- 結果フラグが包括的でない場合あり
スケーリングの問題
- カスケード接続でパフォーマンスが低下
- 幅の増加で電力が増加
- 設計の複雑さが非線形に増加
- テストの複雑さが指数関数的に増加
- レイアウトの課題が増加
- 相互接続がクリティカルになる
- クロック分配がより困難になる
回路実装の詳細
基本ALUブロック図
graph LR
A[A オペランド<br/>8ビット] --> ARITH[算術セクション<br/>加算/減算]
A --> LOGIC[論理セクション<br/>AND/OR/XOR]
A --> SHIFT[シフトセクション<br/>左/右]
B[B オペランド<br/>8ビット] --> LOGIC
ARITH --> MUX[マルチプレクサ]
LOGIC --> MUX
SHIFT --> MUX
OP[演算選択<br/>OP2:0] --> CTRL[制御ロジック]
CTRL --> MUX
MUX --> Y[結果<br/>Y 8ビット]
CTRL --> FLAGS[ステータスフラグ<br/>Z,C,N,V]
フラグ生成ロジック
graph LR
ResultY[Y 7:0] --> NorGate[NOR Gate] --> ZeroFlag[Zero Flag Z]
ResultY7[Y bit 7] --> BufGate1[Buffer] --> NegFlag[Negative Flag N]
CinPin[Carry In] --> XorGate[XOR Gate] --> OverFlag[Overflow Flag V]
CoutPin[Carry Out] --> XorGate
CoutPin --> BufGate2[Buffer] --> CarryFlag[Carry Flag C]
1ビットALUスライス(基本構成要素)
各ビットスライスには:
- 算術ユニット: 加算/減算のための全加算器
- 論理ユニット: 論理演算のためのAND、OR、XORゲート
- シフトユニット: シフト演算のための隣接ビットへの接続
- マルチプレクサ: 演算コードに基づいて結果を選択
演算選択:
| OP2:0 | 選択された出力 |
|---|---|
| 000 | 加算結果 |
| 001 | 減算結果 |
| 010 | AND結果 |
| 011 | OR結果 |
| 100 | XOR結果 |
| 101 | NOT A結果 |
| 110 | 左シフト結果 |
| 111 | 右シフト結果 |
関連コンポーネント
- 4ビットALU: ニブルサイズの演算のための小さいバージョン
- 16ビットALU: ワードサイズの演算のための拡張バージョン
- 32/64ビットALU: 現代のプロセッサ用のより大きいバージョン
- バレルシフタ: 複数ビットシフトのための特殊コンポーネント
- 2進数加算器: 加算のみに特化したコンポーネント
- 論理ユニット: 論理演算のみに特化
- 乗算器: 乗算演算に特化
- 除算器: 除算演算に特化
- 浮動小数点ユニット(FPU): 浮動小数点演算を処理
- SIMD ALU: 複数のデータ要素に対して同じ演算を並列に実行